Unsupervised Learning Algorithms: Machine Learning Series for Beginners
Introduction
Welcome to the fourth blog in our Machine Learning Series for Beginners! In the last blog, we explored supervised learning algorithms, where models learn from labeled data to make predictions or classifications. But what happens when there are no labels? How do we make sense of unlabeled data?
This is where unsupervised learning comes in. In this blog, we will:
- Understand what unsupervised learning is.
- Explore two popular clustering techniques: K-Means Clustering and Hierarchical Clustering.
- See step-by-step Python implementations.
- Learn practical examples and visualizations to make the concepts beginner-friendly.
By the end of this blog, you’ll be equipped with the tools to discover hidden patterns and groupings in your data.

Figure 1 provides an overview of Unsupervised Learning Dimensions, highlighting the core concepts and methods.
1. What is Unsupervised Learning?
Explanation: Unsupervised learning is a type of machine learning where we deal with unlabeled data. Unlike supervised learning, there’s no target output, and the goal is to uncover patterns, groupings, or structures within the data.
The model doesn’t have a “teacher”; instead, it identifies relationships and patterns on its own.
Real-Life Analogy: Imagine you’re at a party with a group of strangers. Without any introductions, you notice people naturally forming groups based on their behaviors — some are at the dance floor, some are at the food table, and others are engaged in quiet conversations. By observing these patterns, you’re clustering people into groups without knowing anything about them beforehand.
2. Applications of Unsupervised Learning
Unsupervised learning is used across industries to analyze and make sense of unlabeled data:
- Customer Segmentation: Grouping customers based on purchasing behaviors.
- Document Clustering: Organizing text documents into topics like sports, politics, or entertainment.
- Anomaly Detection: Identifying fraudulent transactions in finance.
- Image Compression: Reducing the size of images while retaining essential details.
- Social Network Analysis: Grouping users based on interactions and connections.
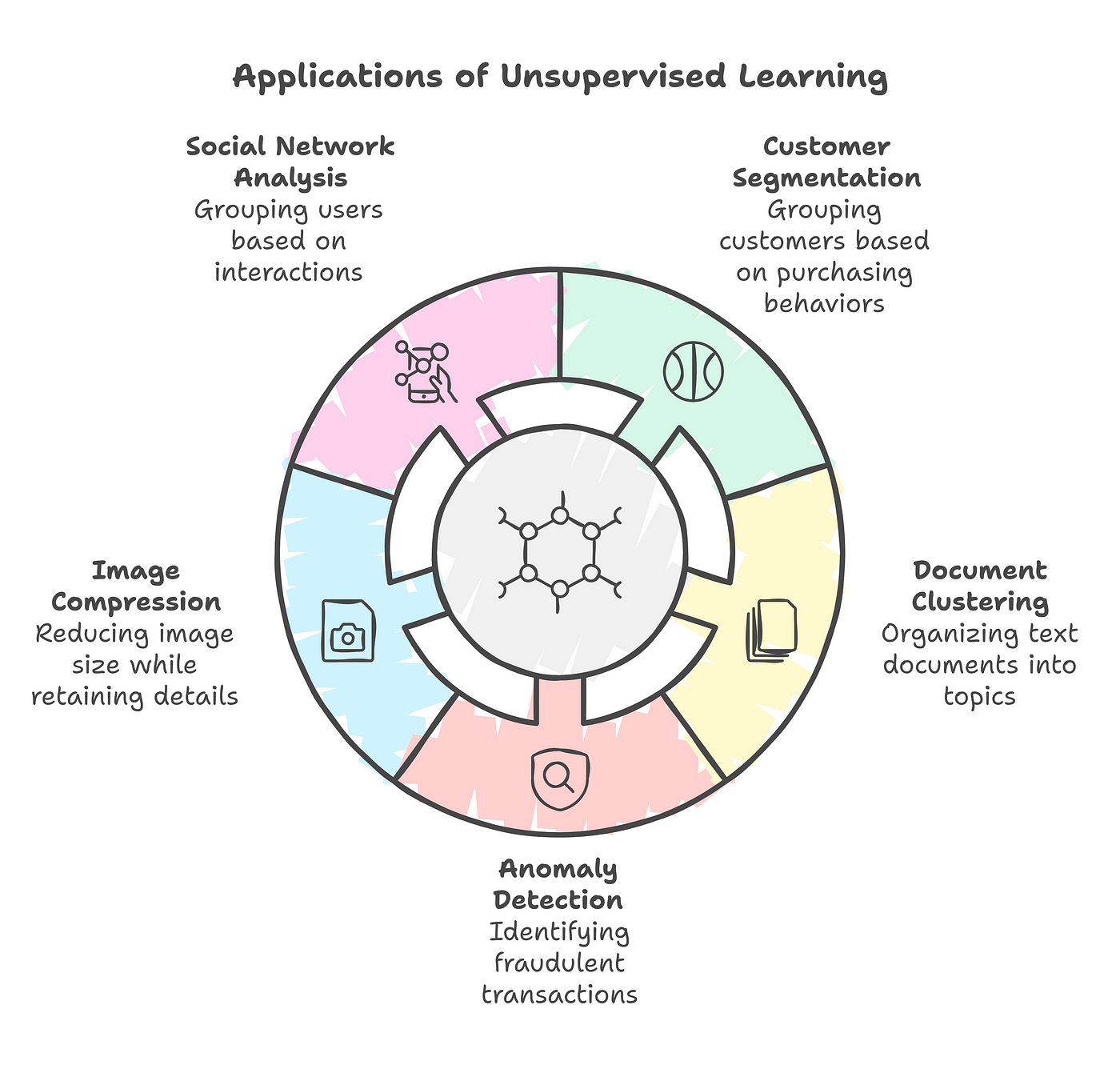
Figure 2 highlights the diverse Applications of Unsupervised Learning, showcasing its versatility across various fields. It illustrates how unsupervised learning techniques are used for tasks like Social Network Analysis (grouping users by interactions), Customer Segmentation (categorizing customers based on behaviors), Document Clustering (organizing text into topics), Anomaly Detection (identifying fraud), and Image Compression (reducing image size while retaining details). This visual emphasizes the real-world impact of unsupervised learning.
3. Clustering Techniques
Clustering is a key technique in unsupervised learning. It involves grouping data points based on similarity.
Let’s explore two popular clustering methods: K-Means Clustering and Hierarchical Clustering.
4. K-Means Clustering
What is K-Means?
K-Means is a clustering algorithm that groups data into K clusters by minimizing the variance within each cluster. The “means” in K-Means refers to the centroids of clusters, which are calculated as the average of all points in a cluster.
Steps in K-Means:
- Select K: Choose the number of clusters to form.
- Initialize Centroids: Place K centroids randomly in the data space.
- Assign Points: Assign each data point to the nearest centroid.
- Recompute Centroids: Recalculate the centroids based on the mean of assigned points.
- Repeat: Repeat the assignment and re-computation steps until centroids stabilize.
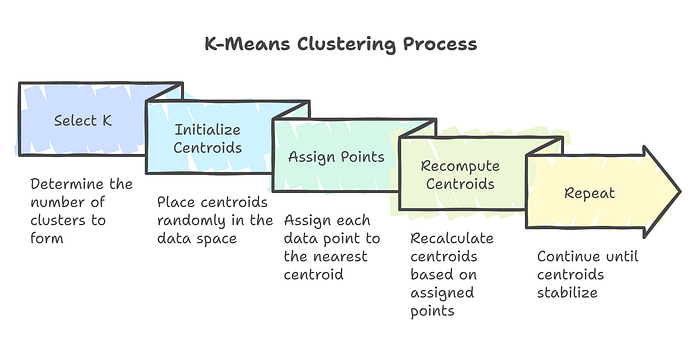
Figure 3 breaks down the K-Means Clustering Process into its core steps. It begins by selecting the number of clusters (K), initializing centroids randomly, and assigning data points to the nearest centroid. The centroids are then recomputed based on the assigned points, and the process is repeated until the centroids stabilize. This visual provides a clear and concise representation of how K-Means organizes data into meaningful clusters.
Example: Customer Segmentation
Imagine a mall manager wants to group customers into clusters based on their annual income and spending habits to target promotions more effectively.
Python Code Implementation:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# Sample dataset: Annual Income vs Spending Score
data = np.array([[15, 39], [16, 81], [17, 6], [18, 77], [19, 40], [20, 76],
[21, 10], [22, 80], [23, 11], [24, 73]])
# Visualize the data
plt.scatter(data[:, 0], data[:, 1], label="Customers")
plt.xlabel("Annual Income (in $k)")
plt.ylabel("Spending Score")
plt.title("Customer Data")
plt.legend()
plt.show()
# Apply K-Means Clustering
kmeans = KMeans(n_clusters=3, random_state=0)
kmeans.fit(data)
labels = kmeans.labels_
# Visualize clusters
for i in range(3):
cluster = data[labels == i]
plt.scatter(cluster[:, 0], cluster[:, 1], label=f"Cluster {i+1}")
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1],
color='red', marker='x', label="Centroids")
plt.xlabel("Annual Income (in $k)")
plt.ylabel("Spending Score")
plt.title("Customer Clusters")
plt.legend()
plt.show()Output: A scatter plot showing three distinct clusters of customers, with red centroids marking the center of each group.
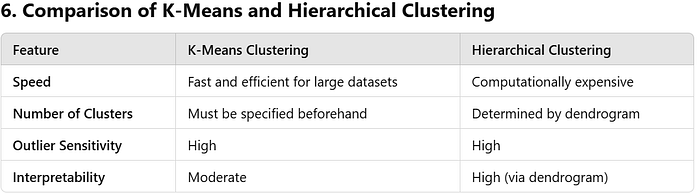
Strengths and Weaknesses of K-Means
Strengths:
- Simple and efficient.
- Scales well to large datasets.
Weaknesses:
- Requires specifying K beforehand.
- Sensitive to outliers.
- Works best for spherical-shaped clusters.
5. Hierarchical Clustering
What is Hierarchical Clustering?
Hierarchical clustering creates a hierarchy of clusters, often visualized as a dendrogram. Unlike K-Means, hierarchical clustering doesn’t require specifying the number of clusters beforehand.
Types of Hierarchical Clustering:
- Agglomerative (Bottom-Up): Starts with individual points as clusters and merges them iteratively.
- Divisive (Top-Down): Starts with all points in one cluster and splits them iteratively.
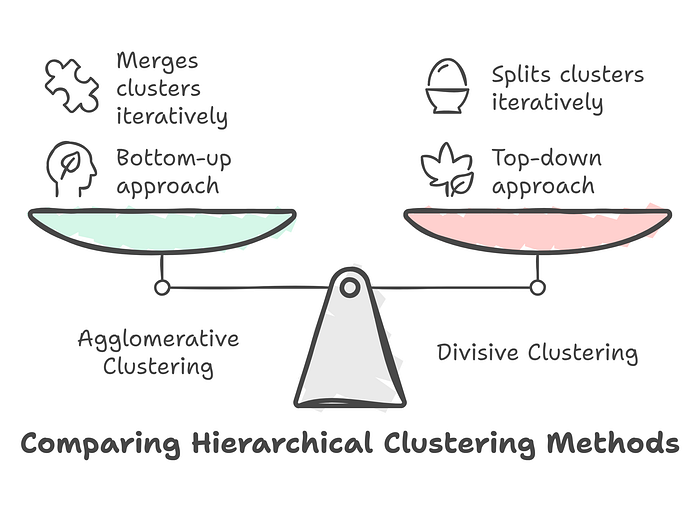
Figure 4 compares the two primary methods of Hierarchical Clustering: Agglomerative Clustering and Divisive Clustering. Agglomerative clustering takes a bottom-up approach, merging individual data points into clusters iteratively. In contrast, divisive clustering follows a top-down approach, starting with all points in a single cluster and splitting them iteratively. This balanced comparison helps illustrate the differences in how these methods construct hierarchical relationships within the data.
Example: Document Clustering
Imagine organizing documents based on word frequencies to group them into topics like “Science,” “Technology,” and “Health.”
Python Code Implementation:
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt
import numpy as np
# Sample dataset
data = np.array([[1, 2], [2, 3], [3, 3], [5, 5], [6, 8], [7, 7], [8, 6]])
# Perform Hierarchical Clustering
linked = linkage(data, method='ward')
# Plot the Dendrogram
plt.figure(figsize=(10, 7))
dendrogram(linked, labels=np.arange(1, 8), distance_sort='descending')
plt.title("Dendrogram")
plt.xlabel("Data Points")
plt.ylabel("Euclidean Distance")
plt.show()Output: A dendrogram illustrating how clusters are formed at different levels, showing the relationships between data points.
Strengths and Weaknesses of Hierarchical Clustering
Strengths:
- Doesn’t require specifying K beforehand.
- Provides an interpretable dendrogram.
Weaknesses:
- Computationally expensive for large datasets.
- Sensitive to noise and outliers.
7. Common Pitfalls and Best Practices
Pitfalls:
- Choosing inappropriate values of K for K-Means.
- Failing to scale features before clustering.
- Ignoring noise and outliers.
Best Practices:
- Use the Elbow Method to determine the optimal number of clusters in K-Means.
- Preprocess the data by normalizing or scaling the features.
- Evaluate the quality of clusters using metrics like silhouette score.
Conclusion
In this blog, we explored:
- The basics of unsupervised learning and its applications.
- How to use K-Means Clustering and Hierarchical Clustering to group data.
- Practical Python implementations with step-by-step explanations.
Unsupervised learning is a powerful tool for uncovering patterns and groupings in unlabeled data. It’s an essential skill for any data scientist or machine learning practitioner.
In the next blog, we’ll dive into Evaluating and Improving Models, covering topics like performance metrics, cross-validation, and hyperparameter tuning.
