Ensemble Learning: Boosting Model Performance — Machine Learning Series for Beginners
Introduction
Welcome to the sixth blog in our Machine Learning Series for Beginners!
So far, we’ve built individual models like Linear Regression, Logistic Regression, and Decision Trees. We also explored how to evaluate and improve models using performance metrics and hyperparameter tuning. But here’s the question:
“What if a single model isn’t enough to achieve the best performance?”
This is where Ensemble Learning comes into the picture.
Ensemble learning is like a team of experts working together to solve a problem. By combining the predictions of multiple models, we can improve accuracy, reduce errors, and make more robust and reliable predictions.
- What ensemble learning is and why it’s powerful.
- Popular techniques like Bagging, Boosting, and Voting.
- Step-by-step Python examples with explanations.
- Real-world scenarios to make ensemble learning relatable and exciting for beginners.
Let’s dive into the power of teamwork in machine learning! 🚀

Figure 1 introduces the concept of Ensemble Learning by illustrating key techniques that enhance machine learning models. It highlights methods such as Voting, Bagging, and Boosting, which combine the strengths of multiple models to improve accuracy and reduce errors. It also showcases foundational models like Linear Regression, Logistic Regression, and Decision Trees, emphasizing how they serve as building blocks for ensemble methods. This figure sets the stage for understanding how combining models can lead to more robust and reliable predictions.
1. What is Ensemble Learning?
Ensemble learning is a machine learning technique where multiple models (often called weak learners) are combined to form a strong learner that improves overall performance.
Key Idea:
- Individual models may be weak or prone to errors.
- By combining them, the overall predictions become more accurate and stable.
Analogy: Wisdom of the Crowd
Imagine you’re trying to guess the weight of a watermelon. If you ask just one person, their guess might be off. But if you ask 10 people and take the average of their guesses, you’re more likely to get closer to the actual weight.
Similarly, ensemble learning combines predictions from multiple models to make a smarter, more accurate decision.
2. Why Use Ensemble Learning?
Ensemble methods are popular because they:
- Reduce errors: Minimize bias and variance in models.
- Improve accuracy: Achieve better performance than individual models.
- Handle complexity: Solve tough problems where a single model may fail.
When to Use Ensemble Learning?
- When a single model underperforms.
- When the dataset is complex or noisy.
- When you want to achieve high accuracy and stability.
3. Types of Ensemble Learning
Ensemble learning can be broadly categorized into the following types:
Bagging (Bootstrap Aggregating)
- Combines models trained on different subsets of data.
- Reduces variance and prevents overfitting.
Boosting
- Builds models sequentially, where each model corrects the errors of the previous one.
- Reduces bias and improves accuracy.
Voting
- Combines predictions from different types of models.
- Improves overall robustness by leveraging model diversity.
Let’s explore each method in detail.
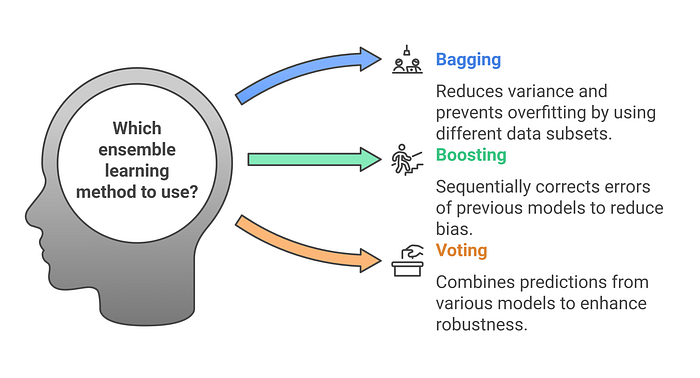
Figure 2 presents a clear comparison of the three major ensemble learning methods: Bagging, Boosting, and Voting. It highlights how each method tackles model improvement in its unique way:
- Bagging reduces variance and prevents overfitting by training models on different subsets of data.
- Boosting focuses on reducing bias by correcting errors sequentially.
- Voting enhances robustness by combining predictions from multiple diverse models.
This figure helps beginners understand when and why to use each ensemble technique to achieve better performance in machine learning tasks.
4. Bagging (Bootstrap Aggregating)
What is Bagging?
Bagging involves:
- Creating multiple subsets of the training data using bootstrapping (sampling with replacement).
- Training independent models (e.g., decision trees) on each subset.
- Combining their outputs using majority voting (classification) or averaging (regression).
Key Benefit: Bagging reduces overfitting and variance.
Random Forest: An Example of Bagging
What is Random Forest?
Random Forest is an ensemble method where multiple Decision Trees are trained on bootstrap samples of the data. The final prediction is made by aggregating their outputs.
Example: Classifying Flowers Using Random Forest
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load the Iris dataset
data = load_iris()
X, y = data.data, data.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Train a Random Forest model
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# Make predictions
y_pred = rf_model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
print(f"Random Forest Accuracy: {accuracy:.2f}")Output:
Random Forest Accuracy: 0.98
Figure 3 outlines the Bagging and Random Forest Process, providing a step-by-step explanation of how bagging works to improve model performance. It begins with creating subsets of data through bootstrapping, training independent models on each subset, and combining their outputs using voting (for classification) or averaging (for regression). The process highlights how bagging reduces variance and prevents overfitting. As a practical application, it showcases using Random Forest to classify flower types, illustrating the power of bagging with decision trees. This visual simplifies the workflow, making it easier for beginners to grasp the concept.
5. Boosting
What is Boosting?
Boosting trains models sequentially. Each new model focuses on correcting the mistakes made by the previous ones. By combining weak learners, Boosting builds a strong model.
Key Features:
- Reduces bias and improves accuracy.
- Works well for imbalanced and complex datasets.
AdaBoost (Adaptive Boosting)
How It Works:
- A weak learner (e.g., Decision Tree) is trained on the data.
- The model assigns higher weights to incorrectly classified examples.
- A new model focuses on these “hard-to-learn” examples.
- Combine all models for the final prediction.
Example: Classifying Data with AdaBoost
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Generate a synthetic dataset
X, y = make_classification(n_samples=1000, n_features=10, n_classes=2, random_state=42)
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Train an AdaBoost model
adaboost_model = AdaBoostClassifier(n_estimators=50, random_state=42)
adaboost_model.fit(X_train, y_train)
# Make predictions
y_pred = adaboost_model.predict(X_test)
# Evaluate
accuracy = accuracy_score(y_test, y_pred)
print(f"AdaBoost Accuracy: {accuracy:.2f}")Output:
AdaBoost Accuracy: 0.89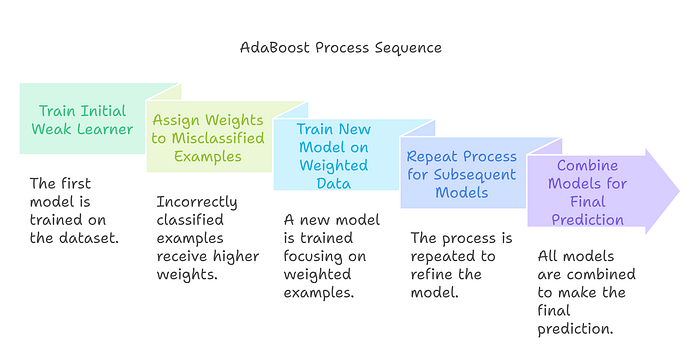
Figure 4 explains the AdaBoost Process Sequence, which highlights how the Boosting technique improves model performance by focusing on errors iteratively. It starts with training an initial weak learner (like a simple decision tree) and assigning higher weights to misclassified examples. Subsequent models are trained on this weighted data to correct the mistakes made earlier. This process is repeated multiple times, and finally, the predictions of all models are combined for the final decision.
This figure simplifies the sequential nature of AdaBoost, showing how it builds a strong model by learning from errors — a key concept for beginners to grasp.
6. Voting
What is Voting?
Voting combines predictions from different models (e.g., Logistic Regression, KNN, Random Forest).
It works in two ways:
- Hard Voting: Majority vote on predicted classes.
- Soft Voting: Average predicted probabilities for better performance.
Example: Combining Models with Voting Classifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load data
data = load_iris()
X, y = data.data, data.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Define models
log_model = LogisticRegression(max_iter=200)
knn_model = KNeighborsClassifier(n_neighbors=5)
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
# Combine models using Voting
voting_model = VotingClassifier(estimators=[
('lr', log_model), ('knn', knn_model), ('rf', rf_model)], voting='hard')
# Train the model
voting_model.fit(X_train, y_train)
# Make predictions
y_pred = voting_model.predict(X_test)
# Evaluate
accuracy = accuracy_score(y_test, y_pred)
print(f"Voting Classifier Accuracy: {accuracy:.2f}")Output:
Voting Classifier Accuracy: 0.97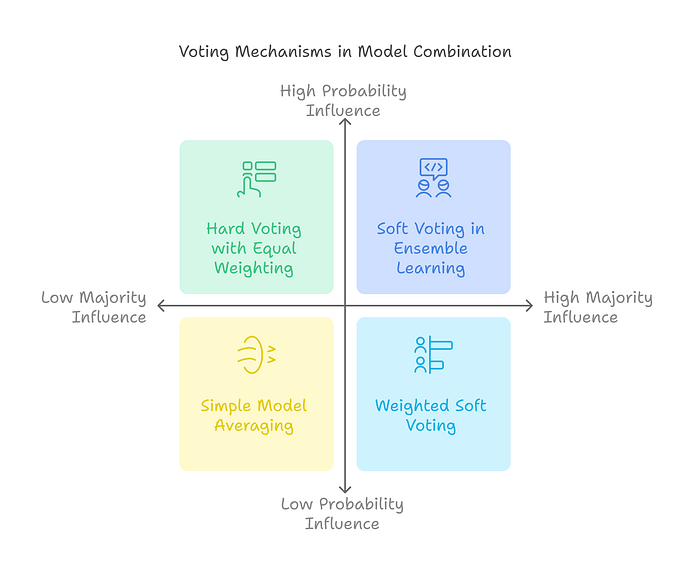
Figure 5 explains the Voting Mechanisms used in ensemble learning to combine multiple model outputs. It categorizes voting methods based on probability influence and majority influence:
- Hard Voting (Equal Weighting): Combines predictions based on majority voting, where each model contributes equally.
- Soft Voting: Averages the probabilities of predictions, leveraging confidence scores for better results.
- Simple Model Averaging: Models’ outputs are averaged with no special weighting, providing simplicity.
- Weighted Soft Voting: Assigns different weights to models based on their performance, giving higher importance to stronger models.
This figure helps beginners understand the nuances of voting techniques, emphasizing how models can collaborate to make smarter decisions.
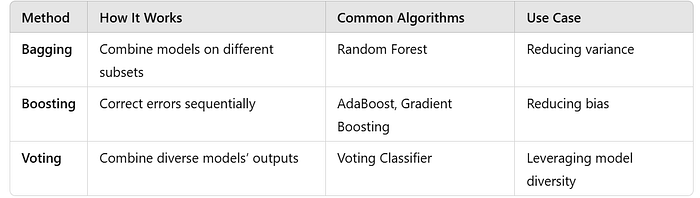
7. Comparison of Ensemble Methods
Conclusion
In this blog, we explored the power of Ensemble Learning:
- Bagging reduces overfitting and improves stability.
- Boosting improves accuracy by correcting errors iteratively.
- Voting leverages the strengths of multiple diverse models.
Ensemble learning is a powerful tool that takes machine learning to the next level by combining models for smarter, more accurate predictions.
What’s Next?
In the upcoming blog, we’ll explore Dimensionality Reduction Techniques like PCA (Principal Component Analysis) to simplify complex datasets.