End-to-End Data Engineering with Apache Spark: Learn by Doing
Imagine you’re working at a large e-commerce company where data flows continuously from various sources — customer transactions, website interactions, and inventory updates. Your task? To build a scalable data pipeline that processes, cleans, and prepares this data for analytics. Apache Spark, with its speed and flexibility, is the perfect tool for the job.
Data engineering is the backbone of any data-driven system. With ever-growing data volumes and the need for real-time processing, Apache Spark has become one of the most popular frameworks for building scalable and efficient data engineering pipelines. This blog post will guide you through how to build data engineering use cases using Apache Spark, from basic to intermediate concepts, with hands-on coding examples.
We will take a structured approach, starting with Spark basics, setting up an environment, exploring data transformations, and finally, implementing an end-to-end data pipeline.
Why Apache Spark for Data Engineering?
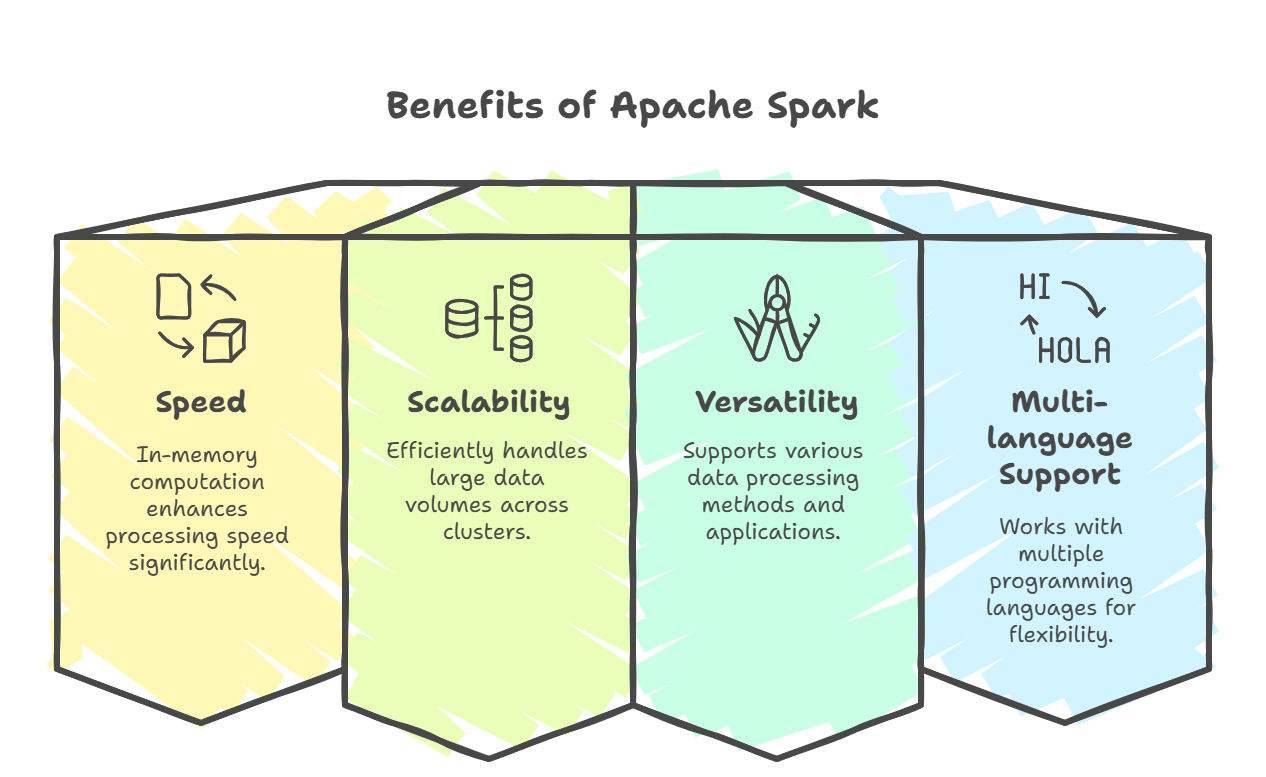
Apache Spark is widely used in data engineering due to its:
- Speed: In-memory computation makes it 100x faster than traditional frameworks like Hadoop.
- Scalability: Easily processes terabytes of data across distributed clusters.
- Versatility: Supports batch processing, real-time streaming, and machine learning.
- Multi-language Support: Compatible with Python, Java, Scala, and SQL.
Setting Up Apache Spark
Before we dive into hands-on coding, let’s set up our environment.
Installing Apache Spark
- Install Java (JDK 8 or later):
sudo apt update
sudo apt install openjdk-11-jdk
java -version2. Download and Install Spark:
wget https://downloads.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz
tar -xvzf spark-3.2.1-bin-hadoop3.2.tgz
cd spark-3.2.1-bin-hadoop3.2/3. Set Environment Variables:
export SPARK_HOME=~/spark-3.2.1-bin-hadoop3.2
export PATH=$SPARK_HOME/bin:$PATH4. Start Spark Shell:
pysparkUnderstanding the Spark DataFrame API
A Spark DataFrame is a distributed collection of data organized into named columns, similar to a table in a relational database. Let’s create a DataFrame and explore its basic operations.
Loading Data into Spark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# Initialize Spark Session
spark = SparkSession.builder.appName("DataEngineering").getOrCreate()
# Load data from CSV
df = spark.read.option("header", "true").csv("data/sample_data.csv")
# Show Data
df.show(5)Basic Transformations
Transformations in Spark are used to modify or filter data.
# Selecting specific columns
df.select("name", "age").show()
# Filtering data
df.filter(col("age") > 25).show()
# Grouping and Aggregating
df.groupBy("city").count().show()# Selecting specific columns
df.select("name", "age").show()# Filtering data
df.filter(col("age") > 25).show()# Grouping and Aggregating
df.groupBy("city").count().show()
Building a Data Pipeline in Spark
Let’s build a simple ETL (Extract, Transform, Load) pipeline using Spark. Imagine we are processing customer data from multiple sources to analyze user behavior and generate insights.
Step 1: Extract Data
df = spark.read.option("header", "true").csv("data/raw_users.csv")
df.show()Step 2: Transform Data
from pyspark.sql.functions import when
# Clean and transform data
df_cleaned = df.withColumn("age", col("age").cast("int")) \
.withColumn("status", when(col("age") > 18, "Adult").otherwise("Minor"))
df_cleaned.show()Step 3: Load Data into a Target Destination
df_cleaned.write.mode("overwrite").parquet("data/processed_users.parquet")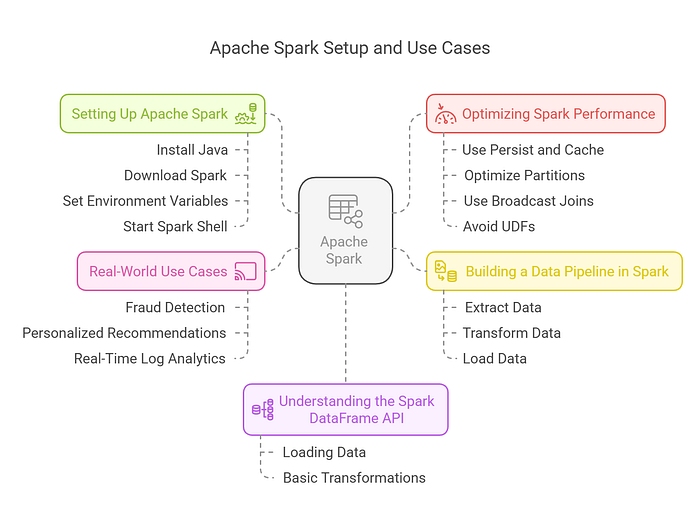
Real-World Use Cases
1. Fraud Detection in Banking
Explanation: Banks process millions of transactions daily, making it critical to detect fraud in real time. Fraudulent activities often involve unusual spending patterns, large transactions, or transactions from atypical locations. Apache Spark helps by analyzing vast amounts of transaction data to identify potential fraud instances.
fraudulent_txn = df.filter((col("amount") > 10000) & (col("location") != "usual_location"))
fraudulent_txn.show()Importance: Early fraud detection prevents financial losses and protects customers. Spark enables rapid analysis of streaming transaction data, identifying anomalies instantly.
2. Personalized Recommendations in E-Commerce
Explanation: Retailers leverage customer purchase history to provide tailored product recommendations. By analyzing purchase frequency and customer behavior, Spark can suggest relevant products, enhancing user experience and sales.
from pyspark.sql.functions import count
recommendations = df.groupBy("user_id").agg(count("product_id").alias("purchase_count"))
recommendations.show()Importance: Personalized recommendations increase customer engagement and sales. Spark processes massive customer data in real-time, ensuring timely recommendations.
3. Real-Time Log Analytics in IT Operations
Explanation: IT teams rely on server logs to monitor system performance, detect errors, and ensure uptime. Logs generate huge amounts of data, and analyzing them in real time allows teams to prevent outages before they impact users.
log_df = spark.readStream.format("json").option("path", "logs/real_time_logs/").load()
log_df.select("timestamp", "log_level", "message").writeStream.format("console").start()Importance: Log analytics improves operational efficiency, ensures faster issue resolution, and minimizes downtime. Spark’s structured streaming enables real-time log monitoring.
Optimizing Spark Performance
To make Spark run efficiently, consider the following optimizations:
- Use
.persist()and.cache()for repeated computations. - Optimize partitions using
df.repartition(10). - Use Broadcast joins to improve performance.
- Avoid UDFs unless necessary, as they are slower than built-in functions.
Key Takeaways
- Apache Spark is a powerful tool for data engineering, supporting batch and real-time processing.
- The Spark DataFrame API makes it easy to manipulate large datasets efficiently.
- Building ETL pipelines in Spark involves extracting data, transforming it, and loading it into a target system.
- Structured Streaming in Spark allows for real-time data processing.
- Optimizing Spark jobs can significantly improve performance.
- Real-time use cases such as fraud detection, recommendation systems, and log analytics showcase Spark’s capabilities.
Here is the mind map for your blog “End-to-End Data Engineering with Apache Spark”:
Conclusion
This blog introduced data engineering use cases with Apache Spark, covering fundamental concepts, real-world examples, and an end-to-end ETL pipeline. By practicing these concepts and experimenting with real datasets, you can master Spark for data engineering.
Data engineering is an ever-evolving field, and mastering Apache Spark will give you a competitive edge in handling large-scale data processing efficiently. Stay tuned for more deep dives into advanced Spark topics like Graph Processing, Machine Learning Pipelines, and Delta Lake integration!
